SC-RNA Cell Type Classification 2
So this problem turned out to be easier than we even thought. We initially needed more labels (150 per class) because the input data was log normalized - we assumed that it was float because of sampling. Our model is a Hierarchical Pitman-Yor Process thatdirectly models power-laws. The log-normalization essential broke our model statistics.
After rectifying that preprocessing error, we were able to get perfect accuracy with only 20 labels of each class and 120 unsupervised labels of each class.
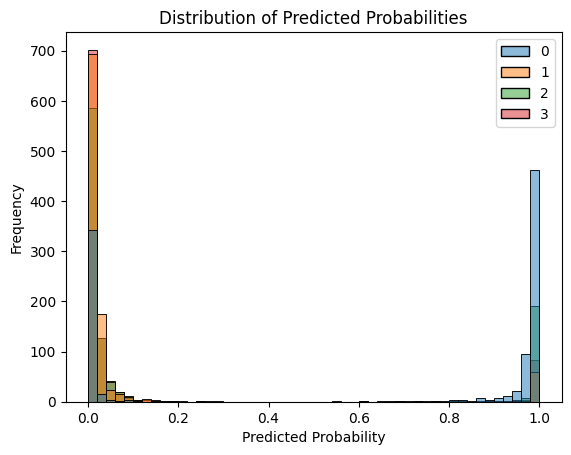
This problem is easy for our model because the ground truth data is to apply some for of PCA-esque dimensionality reduction + UMAP to embed it into 2 dimensions. A scientist will then explore and bulk label the clusters. Our classification model was built to distinguish between classes that are indistinguishable to PCA/UMAP style analysis in text. Remains to be seen if we can offer utitlity to this field beyond the current method.
Some thoughts are exploring cross dataset generalization, dataset integration, etc. Essentially seeing if we can generalize to the point that we can remove any manual step in these annotations, because inspecting the clusters to apply ground truth labels is laborious.
But it’s very cool that we have strong validation that our statistics and infrastructure generalize to rna type data relatively easily.